OpenAI released a speech-to-text model called Whisper, and I decided that I wanted to use that to transcribe conversations on ham radio channels so that I could catch up on what’s been happening while my radio was turned off during the work day.

There are two major parts to this project: getting a live audio feed from a software-defined radio (SDR) tuned to a particular ham radio frequency, then feeding that audio feed into Whisper to do transcription. But first, the hardware:
Hardware

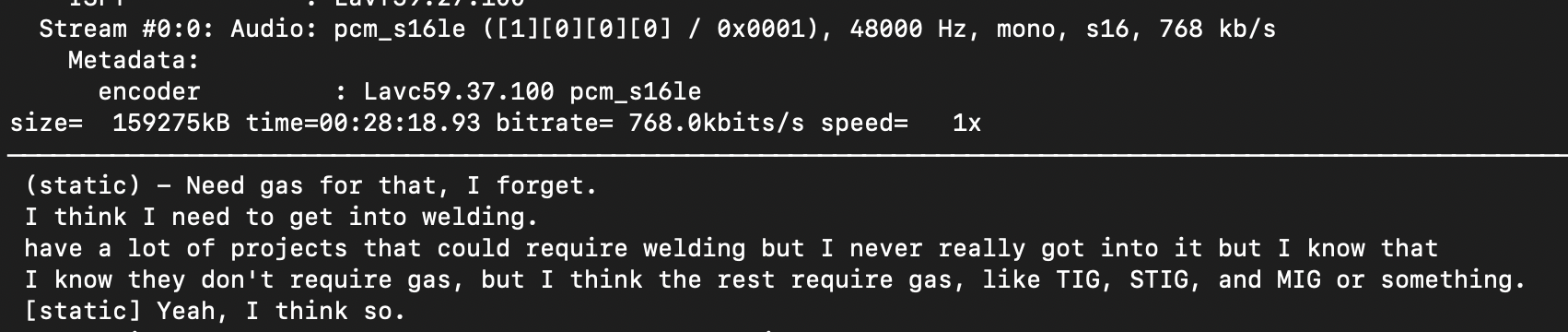
(Image courtesy of KrakenRF Inc.)
I recently bought a Kraken SDR for a related project and I’ve been playing with it quite a bit. It’s basically 5 radios in a single device all tied together with a common clock signal. This allows you to locate the source of a radio signal in real-time, which is awesome, but more on that in a future post. Each of those radios is a pretty standard RTL-SDR so luckily there’s plenty of documentation and guidance out there on how to use it.
Audio
First, we need to create a virtual audio sink which will appear to the operating system as a microphone. We can do this with PulseAudio:
sudo pactl set-default-sink virtualsink
There’s an RTL-SDR software package that contains a program called rtl_fm which can be used to demodulate an FM signal and turn it into a raw audio stream. There’s a program called ffmpeg which is great for real-time transcoding of audio, which can be used to sample this raw audio and convert it into a format we can output to a virtual audio device. Lastly, there’s a program called pacat from PulseAudio which will take an audio stream and output it to a virtual audio device.
Stringing these three commands together, we can create a virtual audio device which appears to the computer to be a microphone, but is really just the audio output from tuning our SDR to a particular frequency.
rtl_fm -d 1 -f 145.33M -s 192000 -M fm - |
ffmpeg -threads 12 -f s16le -ar 192000 -ac 1 -i - -f wav -ar 48000 - |
pacat --playback --device=virtualsink --rate=48000 --channels=1
There’s a lot to unpack here so I’ll go command by command:
rtl_fm
-
-d 1chooses device with index 1 out of the 5 available radios -
-f 145.33Mis the frequency to tune the radio to -
-s 192000sets the sample rate to 192000 samples per second -
-M fmsets the modulation type to frequency modulation (FM) -
-means to output to stdout
ffmpeg
-
-threads 12parallelizes the transcoder across the 12 physical cores on this machine (this probably only needs a single thread, but oh well) -
-f s16ledesignates the input as a stream of signed 16-bit integers with little endian coding -
-ar 192000sets the audio sample rate to be 192000 samples per second -
-ac 1the number of audio channels (mono) -
-i -the input is stdin instead of a file -
-f wavthe output audio encoding -
-ar 48000the output audio sample rate which matches what the virtual audio sink and Whisper are expecting -
-means once again we’re outputting to stdout
pacat
-
--playbackreading audio data and playing it back -
--device=virtualsinkoutputs audio to the virtual sink we created earlier -
--rate=48000matching the sample rate from ffmpeg -
--channels=1again, only a single channel
If everything goes well, you should see output like this:
size= 10902kB time=00:01:56.28 bitrate= 768.0kbits/s speed= 1x
The 1x indicates that the sample rates match up and we’re transcoding in real-time.
Transcription
Georgi Gerganov has created a fantastic port of Whisper called whisper.cpp, HUGE shoutout to him for this incredible work. The typical usage of this project is to take audio from a microphone or audio file and output it as text. In the last section we went to all that trouble to make a stream from a radio look like a microphone so that we could pipe it to Whisper. But first, we have to set it up and pick a model.
Building is pretty straightforward, standard C-based project with cmake. Next, download a model. I chose the medium-sized english-only model but there are larger, more accurate ones available. This one takes a little less than 2GB in memory which isn’t too crazy.
./models/download-ggml-model.sh medium.en
Now it’s finally time to off the transcription. It’s pretty simple:
./stream -m models/ggml-medium.en.bin -t 6 \
--step 5000 --length 5000 -f 145_33mhz-`date +"%Y-%m-%d"`.txt
If all goes well, it’ll prompt you to “start speaking” (again, it thinks you’re using a microphone):
[Start speaking]
You should start seeing text emitted roughly every 5 seconds. I ended up modifying Whisper.cpp slightly to add timestamps at the start of each line which made it a bit easier to read/understand.
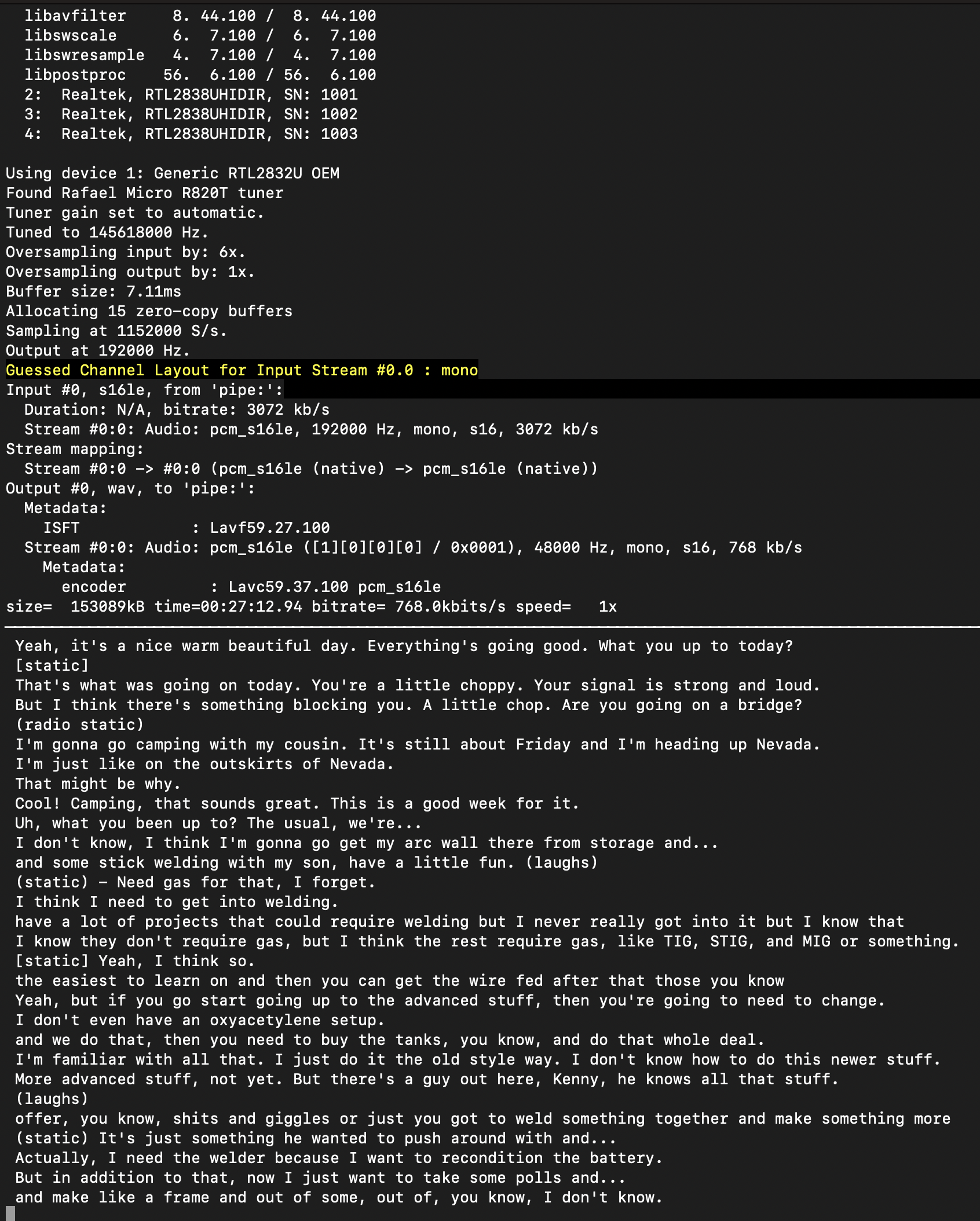
Problems
Unfortunately there’s a bug with how rtl_fm handles squelch settings which means that we’re feeding a lot of static into Whisper when nobody’s talking. This means that most of the transcript contains things like this:
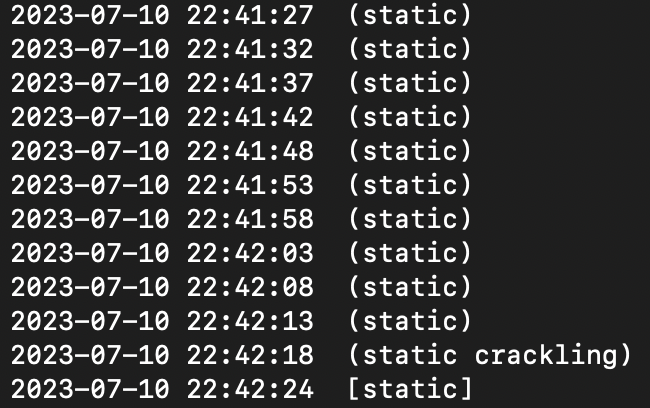
Privacy was a concern early on in planning this project but after consulting with a few different people I’ve gone ahead with it knowing that any ham radio transmissions exist in the public domain and there is no reasonable expectation of privacy. With this in mind, I don’t see any issue with storing these transcripts.